
《笨开发学习操作系统》3内存
OOM 往往是我们经常遇到的 “严重” 问题之一,那内存究竟是如何被合理分配和使用的呢?
本期大纲
- 首先我们要知道一个重要概念就是 虚拟地址
- 虚拟地址和物理地址的映射关系
- 内存中放了什么东西
- 内存是如何分配的
- 内存不够了怎么办
前言
你的电脑上或许此时插着一根 8G 的内存条,你经常在使用它,但你有没有想过操作系统是如何管理内存的?如果让你来分配使用,你是否会想着:给正在运行的游戏分配其中的 4G,给我的视频软件分配 2G,给音乐软件分配 1G,分配各自独立,互不干扰。但当我的游戏需要更多的内存的时候,是否我的视频就无法播放了呢?
那么对于操作系统来说,如何合理的分配和管理好内存就是我们今天要解决的问题。
虚拟地址
首先要引出一个概念:虚拟地址。我们将实际在内存条上存储的地址称为:物理地址。所谓虚拟地址,就是我们人为创建的一个地址,对于进程来说,只能看见虚拟地址。
为什么需要虚拟地址
就像前言中所描述的,如果我们直接都使用物理地址会出现什么问题呢?
- 随着程序的运行,使用的内存不断变化,我们无法预见到需要使用多少内存,无法事先分配;即使事先分配,也会造成使用浪费。
- 如果不事先分配,那么随着内存的变化,进程 A 很有可能增长之后访问到了进程 B 的内存,这是非常可怕的。
所以,虚拟地址提出的原因就是为了一个目标:隔离。进程 A 只能看见自己的虚拟地址,进程 B 也只能看见自己的虚拟地址,互不干扰。
虚拟地址和物理地址如何关联
虚拟地址只是一个虚拟的东西,最终我们的数据还是存放在物理地址上。那么势必需要建立虚拟地址和物理地址映射的桥梁。那么他们之间如何关联呢?
CPU 中的 MMU 就是做这件事的。MMU 叫做内存管理单元,给他虚拟地址,他就能帮你转换为实际的物理地址。那 MMU 究竟是如何做的呢?
你是不是想的非常简单,只需要一个 map,key 是虚拟地址,value 是物理地址,这样不就好了吗?那光是存放这个 map 就花费太多存储空间了。所以我们需要一个合理的数据结构来存放这样的映射关系。
分段存储
分段存储,顾名思义,就是将内存分为一段一段,如:代码段,数据段等等。访问时需要有两个东西:段号、段内地址(段内偏移)。寻址时,通过段号定位到你属于哪一个段,然后通过段内地址,找到在段内的那个部分。
分段机制下,不仅仅虚拟地址会被划分成一段段,实际的物理地址也会被划分成大小不一的段,导致很多内存碎片,就是段与段之间无法利用的空间。
分页存储
为了解决分段机制内存碎片多的问题,于是分页机制就来了。
其实分页机制原理和分段差不多,但是,分页机制的核心点是:将内存分为相同大小的页。
如果有一块蛋糕,让你去分配:有的人要大块,有的人要小块,分到最后你就会发现,有很多小的剩下来了,此时有人问你要一整块大的,那你就分不出来了;如果把蛋糕分成均等的很小份,那么要多的人呢,我将多块一起给你,要少的人呢,即使你用不到最小份,也给你一份,减少了最后剩下来的问题。
分页机制也类似,有着一张页表:通过页号、页内偏移量,来对应最终的物理地址。
但是这样也会带来新的问题,原来我们使用分段的时候,很大的空间算一段,而我们使用分页的时候往往划分就比较小,一般是 4k 一页,假设每个实际物理地址要 8 字节去表示,那么一个 64 位的地址空间需要多少页表才能记录呢?33554432GB … 显然不会这样去记录,而是通过多级页表来实现。
多级页表
多级页表的设计有点像一棵查找的分段树:首先通过 0 级页表找到你在 1 级页表的位置,然后在 1 级页表中找到你在 2 级页表中的位置… 以此类推,最终在 3 级页表中找到最终的实际物理地址。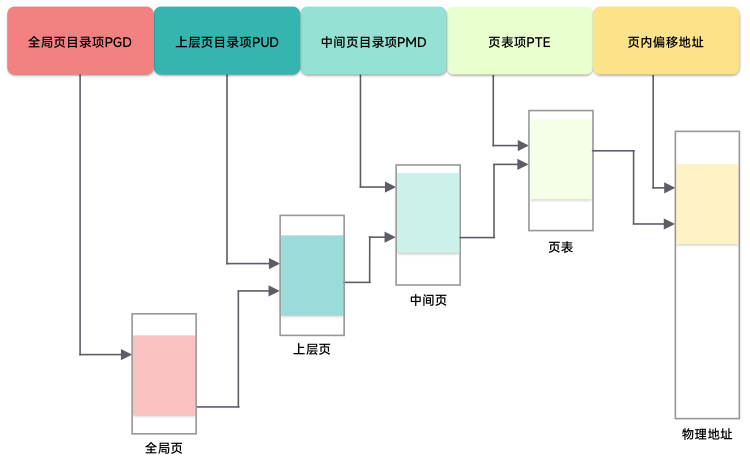
如何更快的找到物理地址
你想,原来如果只有一个表,那么查询的速度肯定很快,找到 key 就能找到对应的 value,但是有了多级页表之后,那么查询的速度自然就受到影响了。所以为了解决查询时间长的问题,那么第一想到的就是加缓存。
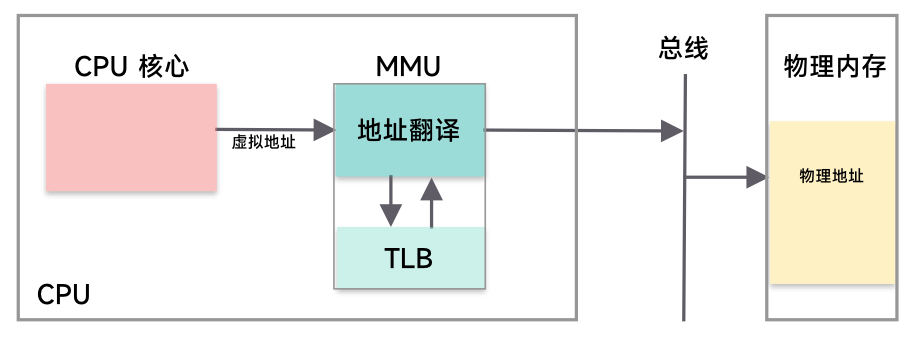
TLB(Translation Lookaside Buffer) 转址旁路缓存,就是做这个的。当 MMU 需要将一个虚拟地址转换为一个物理地址的时候,就会先问 TLB,如果 TLB 知道那么就直接返回,不需要重新进行页表的查询。
根据时间局部性原理,最近访问的内存,那么在未来短时间内被访问多次的可能性较大,故 TLB 其实命中的可能性就很大
但是 我们也要意识到一个问题,不同的进程之间,相同的虚拟地址映射的物理内存是不同的,所以在进程的切换时,会导致 TLB 所有的缓存内容失效,需要刷新 TLB,故进程的切换成本是比较高的。
虚拟内存功能
- 共享内存:允许同一个物理页在不同的进程之间共享
- COW(copy-on-write):写时复制,当我们使用
fock系统调用创建子进程的时候,如果每次都需要将task_struct里面的所有内容都复制一次,那肯定影响性能,于是在共享内存的基础上,有了 COW 机制。当没有修改的情况下,父子进程看到的是相同的内存;当出现修改的时候才进行复制操作。实现方式是,一开始只有只读权限,当修改时会触发缺页异常(违反权限)。 - 内存去重:基于 COW 机制,操作系统会定期在内存中扫描相同的物理页,然后去重,保留其中一个,然后遇到修改时就 COW。Linux 中叫 KSM(Kernel Same-page Merging)
- 内存压缩:当内存不足时,还会触发压缩的机制,Linux 中的 zswap,将数据压缩后节省资源,避免频繁的磁盘操作
- 透明大页:如果内存页是 4KB 的情况下,因为页的数量很多,而 TLB 的缓存项很有限,所以导致很难命中。故使用大页的情况下能大幅度减少页的数量,从而增加 TLB 的命中情况,Linux 提供了透明大页的支持,能够将连续的内存页合并成大页,提高命中的同时还可以减少页表的级数。
内存中放了什么
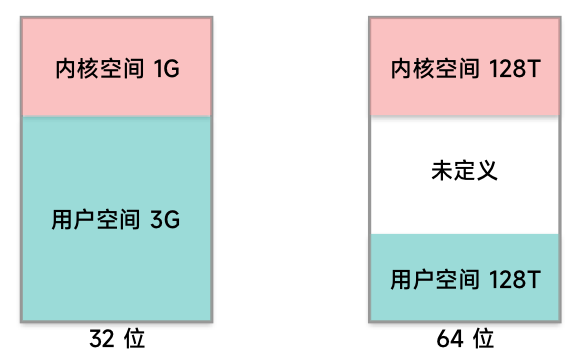
首先有了虚拟地址,全部的地方也并非都是你的,你至少要留一部分给内核。所以一部分为内核空间,一部分为用户空间。32位和64位也不一样,如下图所示:
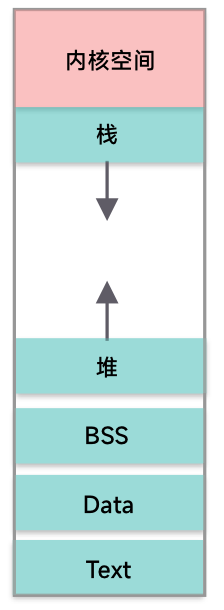
然后用户空间继续细分是 Text Segment,Data Segment,BSS Segment。
- Text 存放代码
- Data 存放静态变量
- BSS 存放为初始化的静态变量
然后就是我们熟悉的堆,用来动态分配内存的区域;栈,函数调用的函数栈
内存分配
首先,我们进程申明了我们要用那么内存,而实际情况往往是用着用着才用到的。那么其实页表中,虚拟地址其实并不一定有相应的物理页的映射,那怎么办呢?
缺页异常
当发现虚拟页未映射到实际的物理页时,就会发送缺页异常,调用缺页异常处理函数,它就会去找到一个空闲的物理页,将这个新的物理页作为这个虚拟地址的映射,称为 swap in。
换页
当我们用着用着发现物理也不够我们使用了的时候,操作系统就要出马了,将一些暂时用不到的内存写入磁盘,然后将这个物理页回收,称为 swap out,这样就能供给给其他进程使用了。
那么哪些是暂时用不到的内存呢?这肯定就需要一个策略去筛选这些不需要的内存了,这其实与缓存淘汰的策略类似:
- MIN 策略:假设操作系统就是知道你以后不用了,那我就淘汰掉它(实际无法实现的)
- FIFO:先进先出,很好理解,先缓存的先淘汰
- LRU:最近最久未被访问的先淘汰
- MRU:最近被访问的先淘汰
- ….
具体我就不一一列举了,都是和缓存淘汰的策略类似的。
虚拟内存的分配
内存的分配有很多的方法和实现,我这里以 malloc 和 TCMalloc 为例。
malloc
malloc 申请虚拟内存方式为 (注: glibc版本不同实现不一致):
- 申请内容小于 128KB 时,使用
brk系统调用 - 申请内容大于 128KB 时,使用
mmap系统调用
当然 malloc 也有优化,因为如果每次都进行系统调用那势必来回在内核态和用户态切换影响性能,同时如果堆从下向上增长的时候下方的内存没有被释放,高地址不能被回收,会产生内存碎片。
所以 malloc 先申请一块大内存到自己的内存池,然后每次从内存池中进行返回和处理,相当于加了一层缓存。当 free 释放内存的时候不会马上还给操作系统,而是先到内存池中,以便下次继续使用。
TCMalloc
tcmalloc 是 google 开发的内存分配器,据说它的内存分配速度是 glibc2.3 中实现的 malloc 的数倍。
前面的 TC 两个字母意思是:Thread Cache ,也就是每个线程各自独立的 cache。它设定了一系列的概念:
- page 内存管理的单元
- span 由多个 page 组成
- ThreadCache 每个线程独立的 cache
- CentralCache 当 ThreadCache 内存不足时提供内存
- PageHeap 当 CentralCache 不足时提供内存
由于 tcmalloc 的细节非常多,内部结构也较为复杂,这里并不详细讨论,给出简单的分配流程:
- 小对象 0-256KB :ThreadCache -> CentralCache -> HeapPage,绝大多数情况下本地线程的 ThreadCache 就足够满足小对象的使用了,所以无需额外的系统调用,也无锁,分配效率很高
- 中对象 256-1MB:直接在 PageHeap 中找到合适大小分配即可,其中有各种各样的 span 满足分配的需求
- 大对象 > 1MB:从 PageHeap 中的 large span set 选择合适数量的页面组成 span
总的来说就三点:一个是按需分配,根据不同大小的对象来合理分配,一个是针对小对象进行缓存,并且设了一个三级缓存有 ThreadCache 还有 CentralCache,还有一个是针对大对象的特殊处理。
物理内存的分配
在物理内存使用的时候,我们很多时候最关注的一点就是碎片的问题,内存碎片越少,内存资源的利用率也就越高。
伙伴系统(buddy system)
于是伙伴系统就被设计了出来,它的基本思想很简单:
- 多个连续的物理页组成块,页数为 2 的 n 次幂,如:1,2,4,8…
- 通常在资源足够的情况下,无论用户需要多少页的内存,都可以分配合适的块组合分给用户,如:需要 5 页 5=4+1
- 当所需要的块不够的情况下,会进行分裂,如:需要 5 页,原本是 4+1,但是 4 不够,就会将 8 拆分为两个 4
伙伴系统的设计思想其实和二进制一样,一个十进制转换为二进制之后就类似这里的使用 2 的 n 次幂来分配类似。
SLAB 分配器
但是,如果只有伙伴系统也还有问题,内核常常需要分配的内存大小往往是几十个字节,远小于一个物理页,那每次都分一页也太浪费了。所以就有了 SLAB 分配器,专门处理这种小内存的分配工作。
SLAB 简单来说就是做了一层缓存工作,缓存大量常用的已经初始化的对象,每次申请这类对象时,就从缓存中分配出去,当要释放回收时,也不会直接返回伙伴系统,而是返回缓存中。
总结
从操作系统内存的学习我们其实能够学到很重要的几个设计理念:
- 数据隔离:通过虚拟地址这个设计很好的将不同进程之间的数据进行了隔离,而且并不会影响进程原本的使用,对于进程来说是透明的。
- 多级页表:通过多级页表的设计能极大程度的减少存储的空间,并且能保证查询的速度,这样的设计在很多地方都有体现,如 redis 的跳表。
- 位分幂和:无论是
tcmalloc还是伙伴系统,其思想都类似,先分成最小单位,然后根据 2 的指数次进行组合,组合出各种各种可能来减少碎片,这里有着一些二进制的思想。 - 分类讨论:同时,分配的时候都带有分类讨论的思想,针对小对象如何处理,如何优化分配;针对大对象如何处理。这种优化在实际中常常用得到,特别是一些 GC 的语言。
- 缓存:这个就很基本了,无论是
TLB帮MMU缓存,还是Thread Cache缓存,都有缓存的身影。
总之,针对操作系统的内存,我们要知道它这样设计的目的,还需要知道它其中做了哪些优化,这些优化是为了什么,这些思想在我们以后的开发过程中是否有可以借鉴的地方。
参考链接
 微信
微信 支付宝
支付宝






