]]> 前言
AI 带火了向量数据库,来对比几个不同的向量数据库,使用感受和差异,个人非标测试,仅供参考。
具体每个我就不多介绍了,官网都有
使用场景
正所谓不设定场景的测试和比较都是耍流氓,所以先说明一下使用场景。由于大厂的技术选型往往就直接冲着数据量、扩展性等等方向去了,而这次我们的角度不一样,更贴近与个人用户使用,准备用在个人项目中,并且直接安装在个人电脑上。
- 本来就是单点,不需要考虑什么扩展
- 数据量不大,一个人撑死能有多大的数据
- 使尽可能减少资源占用
安装
全部使用 docker 一把梭,使用的宿主机相同配置,都是足够的。
milvus
其中 attu 是专门用来查看的,默认自带的功能比较少,没法直接操作
1 | version: '3.5' |
pgvector
pgvector 是 postgresql 的一个插件,所以安装之后需要执行命令去启用
1 | $ docker run --name postgresql -e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password -p 5432:5432 -d pgvector/pgvector:pg17 |
1 | $ docker exec -it postgresql psql -h 127.0.0.1 -p 5432 -U postgres |
1 | $ postgres=# select * from pg_extension; |
1 | $ postgres=# CREATE EXTENSION vector; |
qdrant
1 | docker run -p 6333:6333 -p 6334:6334 qdrant/qdrant |
elasticsearch
1 | docker run -d \ |
测试
前提
- 相同的向量数据,是同一个模型
embedding生成相同的向量数据,维度 1024 - 相同的索引算法, HNSW (Hierarchical Navigable Small World)
- 相同的计算方法,COSINE 余弦相似度
查询速度
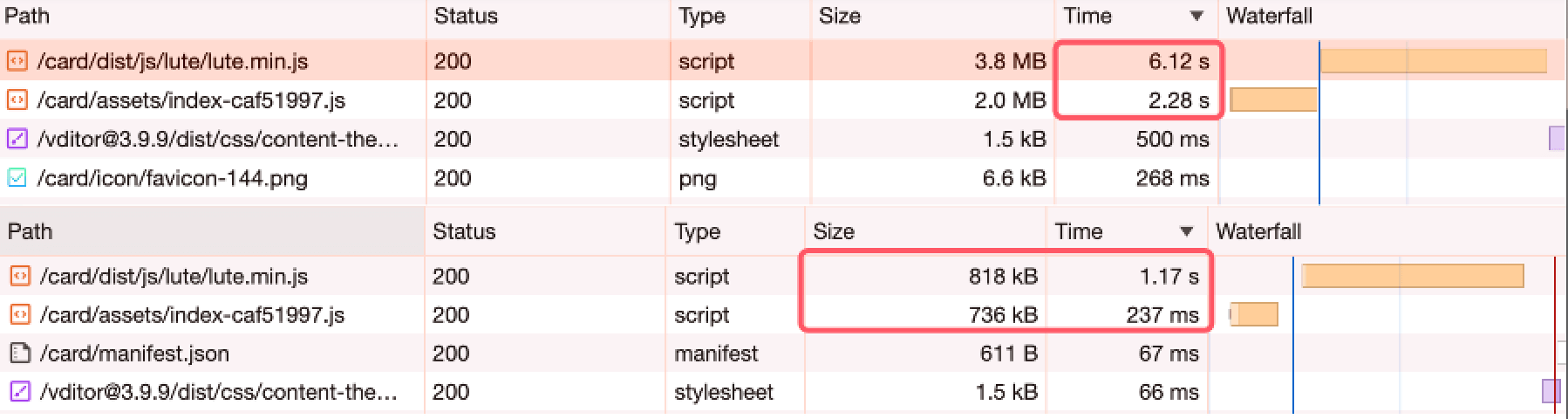
小数据量下区别不大,大数据量下这个差距会扩大
- milvus 执行时间:452.41ms
- pgvector 执行时间:180.65ms
- qdrant 执行时间:69.00ms
- elasticsearch 执行时间:314.35ms
CPU
pgvector 的 CPU 波动最不明显,qdrant 和 elasticsearch 相差不大,而 milvus 显然 CPU 敏感,测试多次效果基本一致。

内存

从内存的角度上来说,很明显 elasticsearch 和 milvus 占用更多,而 qdrant 和 pgvector 从图片中很难看出区别,但实际数据值可以看到一个是 172MiB(pgvector) 一个是 152.9MiB(qdrant) 也区别不大。
1 | CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS |
使用
我使用的 go 连接的每个数据库,具体代码就不展示了,每个仓库的使用方式的各有不同,但好在 sdk 都完整所以直接将官方的案例拷贝过来都能用。说几个实际中遇到的问题。
milvus
相比于其他几个,它的使用需要额外在查询之前 LoadCollection ,需要手动 load 到内存里面去。然后如果使用完之后不用了,可以关掉。
解析结果的时候一定注意查询结果还在内侧,而非最外面
1 | searchResult, err := m.client.Search( |
别问我怎么知道的,说多了也难受,不知道为什么要这样设计…
pgvector
如果没有使用 orm 的话需要手写 SQL 相较于其他的 API 使用会有一点点门槛,比如:
1 | SELECT title, 1 - (embedding <=> $1) as similarity |
其他
一定注意使用的索引算法和向量的维度,有的时候创建的维度和插入数据维度不一样也不会异常报错的,需要特别注意。特别是在测试不同模型下生成不同维度向量数据效果的时候。
查询结果的说明
从理论上来说在使用相同算法的情况下,无论哪一个数据库查询结果应该都是相同的
实际测试下来发现
- milvus
- qdrant
- elasticsearch
相同的查询条件下,以上三者的查询结果相同,而 pgvector,在一些查询条件下结果与其他会有一两个差异,相似度越高差异越小,比如 top5 就没差异,top10 可能就相差一个。这是由于 pgvector 实现的算法逻辑应该是近似的,而非 100%,不过不影响实际使用,后面会有说明。
总结
- 注意,搜索结果与使用数据库无关,仅与算法有关。
- 由于有索引存在,不同的向量数据库在个人使用的场景下均能满足对于查询速度的要求。
- 插入,虽然这里的测试并没有提到插入数据,因为实际的使用中对于插入数据来说并不敏感。但由于测试的时候插入的数据量巨大,导致明显 qdrant 遥遥领先于其他插入的时间,对于测试会友好很多。
个人总结:
在其他条件类似的情况下,显然使用不同底层语言实现的,计算和内存资源的使用上 Java(elasticsearch) > golang(milvus) > rust(qdrant) ≈ c(pgvector) 感受太明显了,所以那么多人才会用 rust 去重写各种中间件。没办法,底层就直接决定了能力所不同。
单一向量方式的的相似度对于搜索来说有效,但还不够,一方面取决与向量化模型本身,另一方面用过的都知道,仅用 COSINE 余弦相似度去比较,最终的查询结果没有那么的符合人的直觉。所以才会有那么多的搜索系统才有召回、粗排、精排、匹配。所以,单一能力并不能足以胜任工作,如果做的更准,还有很多工作要做的。当然,对于个人使用者来说,就我的使用感受来说,显然比一些正常的分词后做匹配要来的更好用。
]]>