
《笨开发学习操作系统》2进程
进程和线程有什么区别?一个常常被问到的面试题
我们在实际的开发过程中,经常打交道的就是线程,而进程呢,通常就是我们整个运行的程序。对于他们两个来说其实并不陌生,你要让我说出个一二三也可以讲,但可能也都是从使用的角度,而今天我们就从 操作系统 的角度来重新认识一下他们两个(从内核的角度看进程和线程长什么样)。
大纲:
- 首先我会让你直观感受我们的进程和基本的分类
- 优先理解他们的数据结构
- 状态的变化是非常重要的一环
- 接着是重点:如何创建他们
- 最后再来看调度
你所需要把握的重点是:结构、创建和调度。这些对于以后的开发或是问题的解决都是有着密切联系的。
进程的直观感受
首先让我们从实际角度来直观感受什么是进程,通过 ps -ef 命令可以查看当前进程的相关情况
1 | UID PID PPID C STIME TTY TIME CMD |
可以看到有非常多的进程在运行,可以简单的看一下:
- 1 号进程它的父进程是 0 号,是 systemd
- 2 号进程它的父进程也是 0 号,是 kthreadd
- 后面其他的进程都是由 1、2 号进程 fock 出来的
- 在 CMD 一列中,带有中括号
[]的进程是内核态的进程,PPID 也就是父进程是 2 号进程kthreadd - 还有其他进程,如我们正在使用的命令
ps的进程就是 28030, 它的父进程就是 27703 也就是 bash,它的父进程的父进程就是 27701 也就是我们的 ssh
进程的定义
我们可以根据不同的角度给进程下一个定义:
- 从用户角度看:进程是应用程序运行的一个实例
- 从功能角度看:进程是应用程序运行所需资源的容器
- 从操作系统角度看:进程就是一些数据结构
进程的数据结构
既然我们是学习操作系统,那么自然就应该从操作系统的角度去分析进程到底里面有些什么东西。在操作系统中,每个进程都需要一个数据结构来保存相关信息,这个数据结构称为 **进程控制块 (PCB Process Control Block)**。
结构图
在 Linux 中 PCB 被命名为 task_struct 这个结构非常复杂,里面有着很多进程在运行过程中所需要的信息,整体结构图如下。
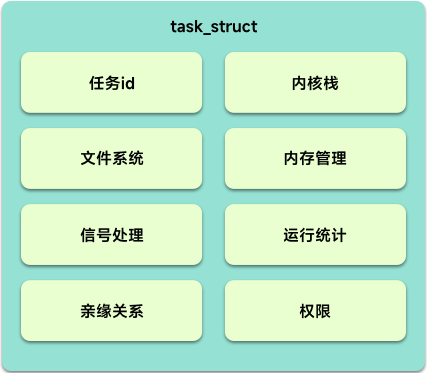
ID
首先肯定需要一个唯一标识,去标识进程。
- PID(process id) 进程唯一标识
- TGID(thread group id) 线程组id,对于同一个进程创建的所有线程,tgid 是相同的,就是主线程的 pid
信号处理
操作系统需要去控制进程的状态,肯定需要一些手段,而信号就是手段,进程需要处理操作系统发给它的信号从而做出相对应的反应。所以进程中有一些特定的结构来接收处理对应的信号。
举例来说,我们常常会使用 kill 命令 “杀进程” ,这个操作就是给进程发送了一个信号,让它关闭。
状态
当然我们需要一个状态标识,去表示当前进程的状态,是已经停止了(TASK_STOPPED)?还是正在 运行等待分配 CPU 来执行(TASK_RUNNING),还是已经睡着了(TASK_INTERRUPTIBLE)。
进程调度
当有很多进程都在运行的时候,操作系统肯定需要管理这些进程的运行,毕竟 CPU 只有一个,那么谁先运行,谁后运行就很重要了。
那么进程中就需要一些字段来保存如:优先级,调度策略,可以使用哪些 CPU 等等的相关信息了。
其他
- 亲缘关系:因为进程的创建也是由父亲创建孩子一步步来的,所以需要记住自己的父亲是谁
- 进程权限:rwxr–r–?777?熟悉吗,这些权限就限制了进程能做什么不能做什么,能被谁使用和不能被谁使用
- 内存:当然进程需要有内存,那就需要有自己独立的虚拟内存空间,
mm_struct就是用来表示它的 - 文件:进程还需要访问对应的文件和文件系统,也就是
fs_struct
这里我就将进程的几个重要结构罗列了一下,后面还会详细展开,你只需要现在有一个印象就可以了。
其实源码中的 task_struct 字段众多,如果你还想详细了解,我将源码的链接放在了文章的最后。
进程的状态
进程一共有几种状态
我们通常可以通过 top 命令来查看当前系统进程的状态,其中有个 S 一列就代表状态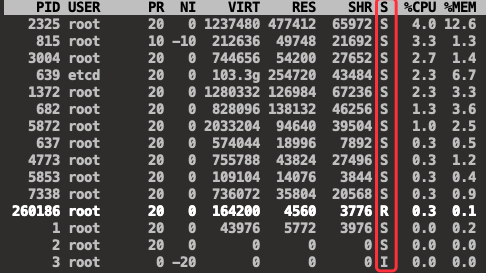
- R 状态(常见):Running 或 Runnable,表示正在运行或可运行(正在等待被运行)
- S 状态(常见):Interruptible Sleep,可中断睡眠状态,表示进程被挂起,等待某个事件发生
- I 状态(常见):Idle 空闲状态,不可中断睡眠的内核线程上,没有任何负载
- D 状态:Disk Sleep 或 uninterruptible sleep,不可中断状态睡眠,表示正在和硬件交互,不允许被其他进程中断打断
- Z 状态:Zombie,僵尸状态,进程实际已经结束,但是父进程还没有回收当前进程的资源
- T 状态:Stopped 或 Traced,表示进程暂停或跟踪,通常为进程接收到了 SIGSTOP 信号
- X 状态:Dead,进程已经死亡,通常你见不到这个状态
状态变化
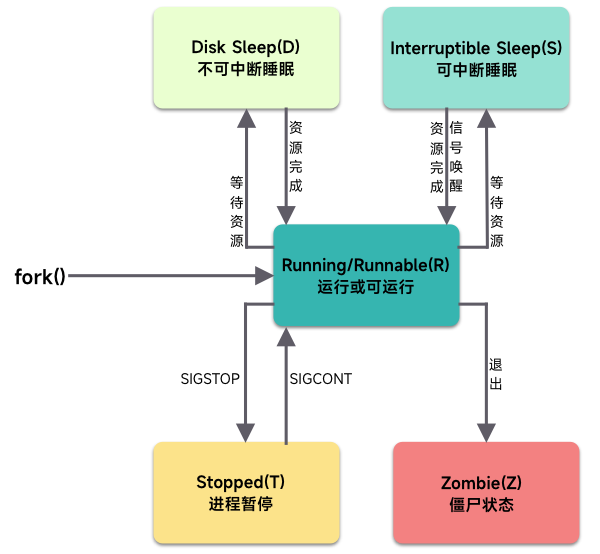
从这张图上我们可以非常清楚的了解到进程状态的改变,其中有几个要点:
- 创建后处于 R 状态,已经被唤醒并等待执行
- D 状态和 I 状态的区别在于,D 状态不接受任何信号(包括 kill)的唤醒,只能死等资源或 IO 完成
- 不能直接从 D 状态不经过 R 直接变成 Z
进程状态的划分在网上我找到了很多划分方式,我这里是借用了 top 命令中的几种状态来进行划分的,并不绝对
创建
进程的创建和线程的创建在本章中是重点,也和我们的开发工作息息相关
进程的创建
创建进程是使用 fork 方法来完成的,所以我们需要搞清楚它做了什么事情
- 复制 task_struct 结构:我们上面已经知道了进程的结构,那么势必第一件事就是将结构给弄出来
- 复制一份父进程的权限,我能操作谁和谁能操作我
- 复制文件系统,存在
fs_struct - 复制信号相关变量,存在
sighand_struct - 复制内存空间
mm_struct - 唤醒新进程,
wake_up_new_task
所以对于进程的创建可以总结为:创建结构,复制老爸,唤醒儿子
线程的创建
glibc 中有一个 pthread_create() 函数,来创建线程
- 创建线程栈
- 调用clone函数
- 调用fock函数
但是这次调用fock函数和创建进程的时候不一样哦,这次调用的时候传入了 clone_flags 标识,当有了这个标识时,原来所有复制的操作就都变成了 引用计数器+1。
比如原来的文件系统相关的结构 fs_struct 应该被复制一份,结果就变成了 fs_struct 的计数器+1。
对比
我们可以从下面这幅图中对比进程和线程的创建结果,你可以简单的理解为:一个是复制,一个是引用。当然复制的成本大,引用创建的成本小。
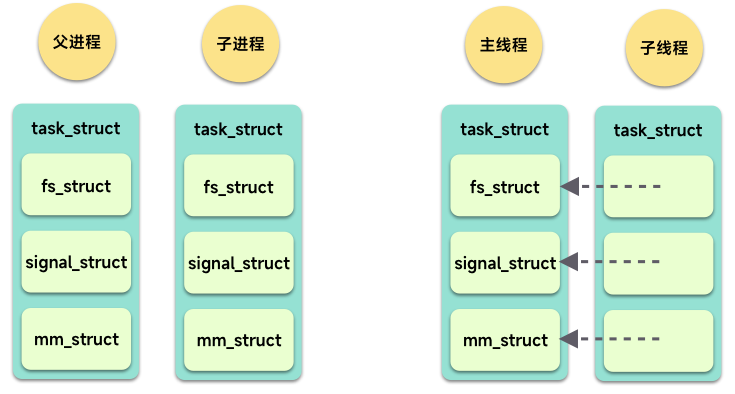
所以从内核的角度看,线程和进程都是一个 task_struct 结构,从表面看好像进程和线程长得一样,但如果内核真的想要认出这个是线程还是进程还是有办法的,可以通过 pid 和 tgid,同一个进程中的所有线程有相同的 tgid
调度
所谓调度,其实就是有很多事情,这些事情有紧急的,有不紧急的,有花时间长的,有花时间短的,如何合理的使用已有的资源让这些事情尽可能合理又迅速的完成,这就是调度所需要做的。
所以吧,操作系统也挺难的,需要我们编写很多调度的策略,根据具体的策略进行调度进程,从而更好的完成任务。
调度策略
实时调度策略
实时调度策略是针对实时进程的调度策略,这些进程的优先级都非常高,对实时性要求高,大家都是紧急的,所以目标是看优先级
- SCHED_FIFO: 先来先做,后来后做
- SCHED_RR: 每个人都做 1 秒钟,即使到时间还没有完成,也只能换下一个,重新排到尾巴去
- SCHED_DEADLINE: 根据 deadline 来调度,哪个任务马上要延期交付了,那它先做
普通调度策略
普通调度就是调度普通的进程,大家都是普通的,所以目标是保证公平
- SCHED_NORMAL: 普通进程,大家都一样,那就公平一点
- SCHED_BATCH: 后台进程,可以默默执行,卡一下也无所谓
- SCHED_IDLE: 空闲的时候才跑的进程,优先级很低
完全公平调度算法(CFS)
CFS(Completely Fair Scheduling) 这算法听上去很公平的样子,其实说起来也很简单,就是我们常说的,CPU 会提供一个时钟,时钟的每一个间隔就会为一个进程安排一个时间 vruntime, 用于记录每个进程运行的时间,vruntime 运行过就会变大,而没有运行过则不会变,所以当那些没有运行过的进程不公平了,就会优先运行它,来补上时间。
这里设计的关键在于,相当于在动态的调整进程的优先级。
调度方式
主动调度
当我们在操作外部设备的使用,往往需要主动让出 CPU 的资源,让操作系统把我们调度走,这样的调度就是主动调度。比如:网络、存储等。方式也很简单主动调用 schedule 方法就可以了。
抢占式调度
- 当前进程执行时间太长
- 当进程被唤醒
显然当进程的执行时间太长,这个时候肯定需要切换到另一个进程去执行了。抢占往往也不是直接就把你从运行的过程中给踢下来了,而是给你一个标记,当可以抢占的时候就会被别人抢占。
还有情况就是当等待 IO 的进程发现 IO 到来被唤醒的时候,此时一会触发抢占。
当前抢占的时机很关键,不能你才读了命令,执行到一半,“卡” 就给你停了。
- 用户态抢占时机:当系统调用返回的时候,此时就是一个正好的时机
- 内核态抢占时机:很多内核态的操作是不能被中断的,可能会先调用
preempt_disable方法关闭抢占,而后面当调用preempt_enable方法打开抢占的时候,此时就也是一个不错的时机
调度的消耗
当前 A 进程正在执行,现在要调度到 B 进程开始执行,那么我们能想到的就是需要将 A 进程当前运行的状态,也就是上下文要保存起来,以便下次 A 进程回来执行的时候知道之前运行到哪里了。同时上下文的切换又分为用户态进程空间的切换和内核态的切换。简单的说,进程的切换是有开销的,且开销比较大。
总结
从进程和线程的创建我们能学到什么?
线程的创建最终和进程的创建使用的都是 fock 方法,但线程的创建不需要复制相关结构,直接使用的是进程的相关结构的引用,故线程确实更加轻量一些,创建所需要消耗的资源也相对较少。
所以,很多语言如:golang,提供了协程的概念,为什么要提供它呢,为的其实就是再抽象一层,让创建worker 能更加更加轻一点,相对线程就所需资源就更加少,调度和切换起来也就更加省力。
从进程的调度我们能学到什么?
其实关于调度的相关算法我们在很多地方都能用到,调度的关键就是能合理分配资源,这样的方法可以应用在 缓存设计、消息消费或是负载均衡等。
从进程的状态变化我们能联想到什么?
在实际生活场景中,很多时候其实最终我们都能将一些场景抽象为一个东西状态的变化,只要能将它的状态变化画出来,作一个状态图,那么很多设计就能更加清晰。这样的状态图在一些软件设计中尤为重要,能让人更加容易理解。
参考链接
 微信
微信 支付宝
支付宝






