
在 Golang 中依赖注入是 解药 还是 毒药?

前言
看到标题,有人可能会疑惑,其实原因是当我在网络上搜索有关 golang 依赖注入、 wire 这些关键词的时候,有一些评论是下面这样的:




有人认为 依赖注入 不应该出现在 golang 中,是毒药
而也有人认为 依赖注入 是非常好的设计思路,是依赖管理的解药
在经过不少项目的磨砺,笔者也终于对依赖注入有了新的认识,但这几个月一直在折腾和纠结,到底要不要写本文。网络上早就已经有了各种讨论有关于 Golang 是否需要 依赖注入 的呼声。今天,我还是觉得将它换一个角度,作为一个个人的小总结和感悟将它记录下来。
故,本文建议推荐给下述人群:
- 还在纠结 golang 要不要使用依赖注入的人
- 对 依赖注入 理解还有所疑惑的人
为了简述,下文有以下简称
依赖注入 简称为:DI
面向对象 简称为:OOP
个人观点
我不喜欢浪费时间,也避免标题党嫌疑,所以为了节约时间,对于已经知道 DI 概念的朋友,直接先给出我自己的观点:
- 如果你现在做的项目不大,或是个人项目,并且还在尝试阶段。完全的面向过程编程,在 go 中是可行的。
- 但如果你的项目比较大,又是多人协作,我真心建议你使用 DI,OOP 是有它存在的意义的。
- 如果你没接触过 DI,那么你一定要尝试去理解它一次,至少给他一次机会,不要盲目听取网络上的声音,实践是检验真理的唯一标准。
或许听上去,我这个观点好像有点矛盾,如果你愿意,请听从我一个过来人,下面几个方面去阐述一下。
为什么我说是过来人呢? 因为我一开始也是使用的 java 做了很久,spring 也是 YYDS,然后转而到 golang 并且一开始也没有使用依赖注入,然后慢慢在学习过程中有了转变,希望从这个路径能给你一些思路
Golang 完全面向过程编程可行吗?
可行!非常明确的告诉你。
我之前有幸参与过前公司一个比较大型的开发项目,由于那个时候刚接触 golang,当时大家都还比较陌生,还在摸索的阶段,当时就是完全使用了面向过程的方式去编程。项目本身包含前端和后台,有 WEB,也有业务,也有各种 SDK 和接口。或许你还对面向过程的方式不太理解,我举几个详细代码例子🌰:
service.GetUserByID(userID)dao.GetUserByID(userID)db.Engine.Find()
你是否有熟悉的感觉呢?如果有,那可能你和我们当时差不多。当时所有的函数都是直接使用包名调用的,不需要初始化,也不需要 new 对象,function 内容 就是 过程。
也有几个显而易见的特征:
- 初始化全部都在 main 里面完成,包括日志、数据库、缓存等等…
- 方法的调用都是直接
包名+方法名 - 相关依赖中间件的调用(数据库引擎、缓存实例等)全部都走的是全局变量,一次初始化,随便哪里都能用
PS:其实,当初这个项目还有一个 1.0 的版本,在 1.0 的版本中虽然没有使用DI,但是当时是 OOP 的思想在做的,我们当时的开发也一致觉得麻烦,所以没有采用。
整个项目现在都还在正常运行,除了 bug 没有问题。
开发完成的感受
- 快速
- 好理解
- 无扩展
整个项目自始至终我们就没有定义过几个 interface 去实现,并且我们当初感觉良好,甚至多拿了点奖金,哈哈。没有意识到任何问题。直到我不断的做项目,换了公司才发现,原来挖坑了。
面向过程开发当时的想法
那时,我对依赖注入的想法可以和某些现在的同学是一模一样的,那时我看到 DI 这个东西就是反感,没有任何去了解的欲望,当时的想法就是下面这样:
- DI == java 的 Spring (当时我看过 spring 的源码,厌恶八股文的同时,也对它有了厌恶)
- 既然我都用 Go 了为啥还要像 Spring 那样非要 New 对象呢?
- Go 为什么还有公司会出 DI 的工具?还会出 Spring 那样类似的框架?
没错,总之那时的我打心底里是不接受 DI 的。我也还停留在 golang NB;less is more 的口嗨当中。
那用了依赖注入之后呢?
直到前两年,我参与了一个新的项目之后,才渐渐的明白,为什么会需要 OOP,为什么会需要 DI。以至于之后的各种项目都有着 DI 的身影。
新的项目
当时由于这个新的项目没有 KPI,所以技术选型可以比较激进,于是我们将很多新特性和方式运用到了这个项目里面,其中就包含了 wire。没错,当时我们只是想了解到底 wire 做了什么,为什么 google 会开发它,我们才去使用的。
其实做项目的时候有些地方比较痛苦,一方面我们需要去了解 wire 的工作方式,一方面由于依赖很多经常会出现一些依赖的问题需要调整依赖关系浪费了很多时间。最后,我第一次有了一些对 DI 的认识。
为什么需要 OOP
理由1: 调用方法前保证初始化
从理论上来说,如果你单单只是通过 包名+方法名 调用方法,那么势必带来的问题就是,你无法保证当前方法内所使用的依赖是一定已经被初始化完成的。
以数据库操作举例:
- 如果是面向过程,你无法保证调用
dao方法的时候,数据库连接已经被初始化完成 - 如果是面向对象,当你调用这个对象的方法前,你一定会
New这个对象,这个对象的相关依赖一定会被传递进去,并且已经被初始化好,所以你可以保证数据库连接已经被初始化完成了。
当然你会说,我早就在 main 函数(或者初始化函数)中初始化过数据库连接了,我一开始也是这样想的,但是后来我发现,你只能说从人为的角度保证了先初始化数据库再使用,而从代码的角度,我其实可以在任意地方调用这个方法。
理由2: 减少全局变量
之前面向过程的时候几乎全部都是全局变量,数据库 ORM 的引擎是全局变量,配置文件的实体结构也是,过多的全局变量会导致的问题和上面一样,在使用时,你从代码层面无法保证使用者是在初始化之后进行使用的。
那么也就是意味着,使用可能会导致空指针,也就是没有初始化好,就已经在使用了。虽然你一样可以说人为的将所有初始化放在 main 中完成。
理由3: 抽象接口,随意切换实现
当你面向过程的时候,你调用某个方法,那就是某个方法,当你想要改变实现的时候,你只能手动切换别的方法。比如从:dao.GetUserFromDB 改为 dao.GetUserFromCache
但是当你使用 OOP 的时候,你可以将原来的依赖改为依赖接口,并创建对象来实现这个接口。当你需要修改实现的时候,上层无需做任何改动,只需要修改实现的对象就可以了。
为什么需要 DI
那么问题来了,OOP 确实有好的地方,但是这与我们讨论的 DI 有什么关系,DI 到底解决了什么问题呢?
既然有了 OOP 就有了对象,有了对象就需要 new,就需要管理对象之间的依赖关系。那么 DI 就是为了解决你不需要 new 对象,不需要手动管理依赖关系的问题。
DI:Dependency Injection 依赖注入。如果你是第一次见到这个概念,或许还对这个概念比较陌生。
我也是从 java 过来的,在 java 中 spring 框架中就有这个概念,当时我在学习 java 的时候就有所了解,但其实当我在 golang 中实践了之后有了更深刻的认识。
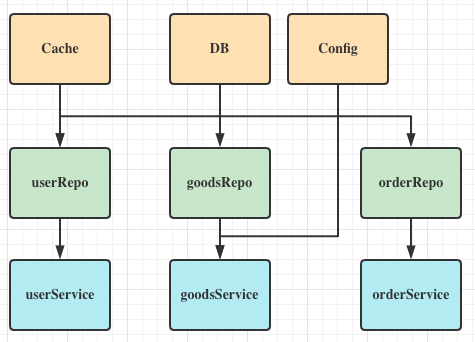
如图,我随便画了一下可能存在的普遍依赖关系,那么就会遇到下面几个问题:
先有鸡才能有蛋
首先,如果我们需要调用一个对象的方法,那么第一步需要 new 这个对象。比如,我们需要使用 userRepo 的 Get 方法,首先我们需要有 userRepo 对象才可以。这就是面向对象的第一个问题,先有鸡才能有蛋。
先有母鸡才能有小鸡
然后,当我们的对象依赖于其他对象的时候,我们需要先初始化其他对象,然后将其他对象传递进去才能进行当前对象的初始化。比如,userRepo 对象需要先初始化数据库 Engine,那么我们就需要先 new Engine 对象,然后才能 new userRepo 对象。这就是面向对象的第二个问题,先有母鸡才能有小鸡。
鸡的亲戚关系难管理
最后,由于对象很多,依赖会越来越复杂,如果我们手动去管理这些依赖,那么就会非常麻烦,并且依赖的先后顺序很难被理清楚,特别是当新的依赖被添加的时候。这也就是第三个问题,鸡的亲戚关系难管理。
为了解决这些问题,于是依赖注入就出现了。有了它,最大的特点就是,你不需要 new,也不需要主动去管理依赖关系。
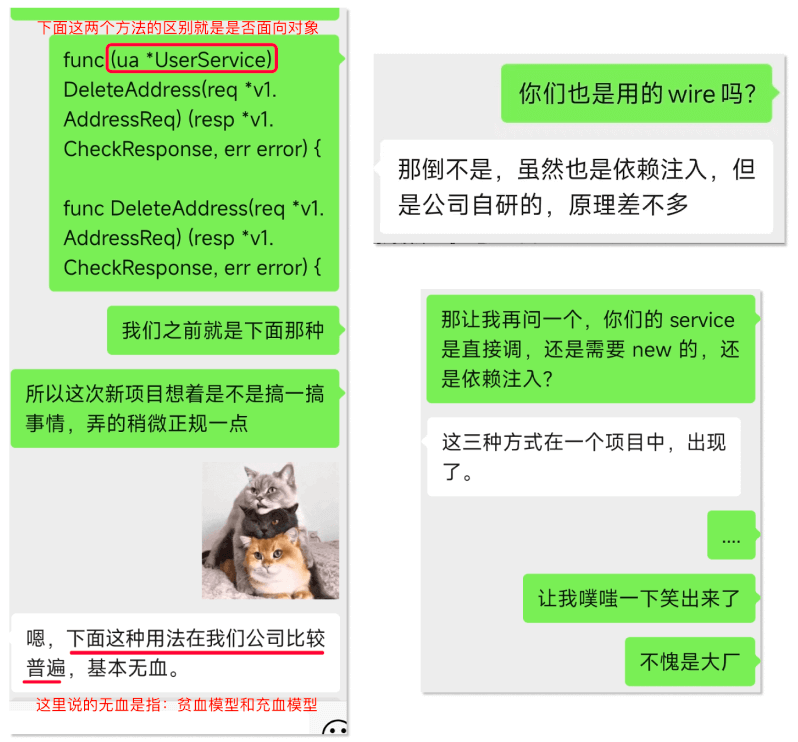
一开始,我接触 Java Spring 的时候常常会听到一句话,有了 spring 你就不用 new 对象了,其实刚学习的时候个人完全不理解,完全是一种被动接受,别人写
@Autowired,我也这么写
使用 wire 实现 DI
在 golang 中实现 DI 最常见的两个库一个是 dig 一个是 wire 。实现思路上,dig 使用的是反射,而 wire 使用的是代码生成。反射肯定会有性能损失,而 wire 在我使用的过程中还是挺不错,所以这里用 wire 来讲述具体使用情况。
base code
首先,我们定义一些结构来模拟我们经常做的 web 项目的初始化过程。
1 | type DB struct { |
不使用 wire
如果不使用 wire, 我们可以通过手动 new 的方式初始化
1 | func main() { |
使用 DI
需要使用 wire 的话,首先需要创建一个 wire.go 的文件用于生成代码,申明了最初始的入参和最终的产出物
1 | //go:build wireinject |
然后我们只需要在使用的地方调用对应的初始化方法获得产物即可,不需要关心其中的依赖关系。
1 | func main() { |
最后使用 wire . 命令就可以生成对应的依赖关系和初始化过程
1 | // Code generated by Wire. DO NOT EDIT. |
其实,我们可以看到生成的代码和我们手动写初始化的代码几乎一模一样。到这里你可能会觉得,那么我自己写不是也可以吗?没错,在项目小的时候几乎看不出来优势,但是当项目大了,有许许多多资源的时候初始化就会变得非常复杂。
并且,如果你需要做优雅关闭的时候,你需要顺序将依赖一层层的停止:
比如你是先初始化数据库,再初始化缓存,最后启动 http 服务;那么相对应的停止的时候,你应该先停止 http 服务,再关闭缓存,最后关闭数据库连接。* 如果你先关闭数据库连接,http 服务依旧存在,访问就会出错。*
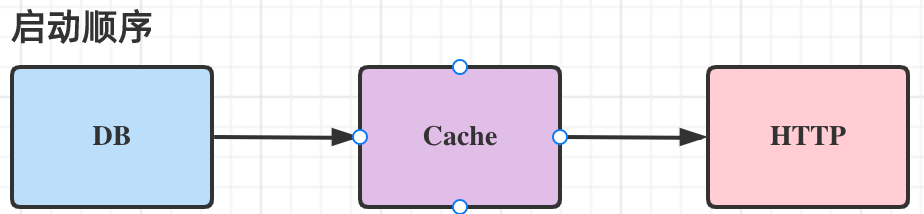
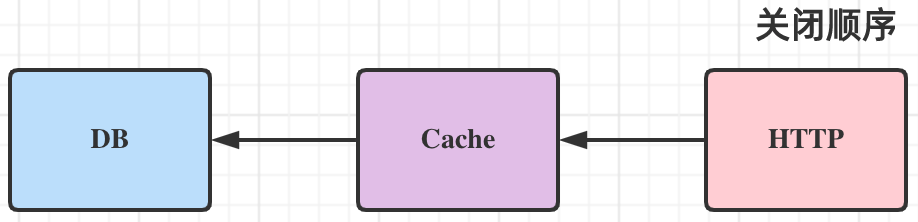
而 wire 在每个 new 方法中支持三个参数,对象,cleanup,error,其中第二个参数 cleanup 就会在关闭的时候按照依赖的倒序依次进行关闭。
所以 wire 做的事情就是根据你 new 方法的入参和出参,识别了他们之间的依赖关系,生成了对应的初始化代码。
项目表现
最后当我们使用了依赖注入之后,体现在项目中的使用情况具体表现:
- 我们再也没有关心过对象依赖关系初始化顺序和 new
- 由于我们依赖的是接口,实现的切换几乎是无痛的,在上层也感知不到数据的来源变化
- 全局变量说拜拜,再也没有出现说用某个东西空指针,”哦,不对还没有初始化” 的尴尬
对比
那么问题来了,就如标题所说的,到底 DI 是解药还是毒药?在网络上搜索 golang 依赖注入,或者搜 wire,许许多多的人会在下面评论,golang 不需要 DI,把 DI 认为是毒药。golang 就应该简单。DI 完全是徒增代码复杂,并且还多了概念需要让人理解。
其实,我在一开始写 java 的时候就问过这个问题,为什么 java 里面不将所有的方法都声明成 static 这样都不需要 new 直接调用就可以了。
但是当我磨砺了很多项目之后,我就有了更加深刻的理解,为什么之前的人会想要这样去设计,所以我觉得这个问题可以从两个方向上来看:
为什么我之前的项目完全面向过程没有问题
- 所有依赖在一开始就完成了初始化,并且依赖只有配置文件、数据库和缓存
- 项目本身功能几乎没有二次周期的迭代,功能非常直接,已有功能没有调整,只有新功能的添加
用了 DI 带来了什么收益
- 减少了全局变量
- 理清楚了初始化的依赖关系,并且从代码层面保证你使用时,相关依赖已经初始化完毕
- 可以依赖接口,按需切换实现
结论
回过头来看我一开始说的观点其实就不矛盾了,就拿我自己举例来说,如果是一些小项目,并且很多时候 go 并不是做 web 开发,更多的是做工具那么 DI 有时候并不一定需要。
但是对于一些大项目来说,我觉得为了以后的考虑,还是别挖坑了,无论是从消除全局变量还是扩展性来说,DI 或者说 OOP 都是非常有必要的。
然后,有两点非常重要:
- DI 可以从代码层面直接限制你,依赖必须要初始化才能使用,我非常认可这点
code is law代码框架即约定可以从很多时候避免问题。一个好的框架,应该从代码层面直接限制掉很多问题的发生,而不应该依赖于程序员的口头约定或者文档约定。 - DI 可以解耦实现,这点也很关键,我知道并非所有的项目都会有改造实现的需求,但是依赖倒置这样的设计模式往往能给以后的扩展提供更好的支持,并且这样的设计思路可以运用在很多代码的其他设计上。
当然,也有两点值得提醒:
- 使用 DI 并非一定绑定一个工具,并不是一定要有 wire 或者 dig,如果你的依赖只有一两个手动管理也并非不可,正常的 OOP 也可以写的很优雅。
- 也不是所有全局变量都要一棒子打死,你用
sync.Once写个 单例模式,也是非常不错的设计。
最后,我觉得,如果你从来没有用过 DI 或者没有理解过它的思想,那么请你用一次,至少明白它的设计思路,或许在别的设计方向上可以给你启发。任何语言都不应该有刻板印象,java 的 spring 并非在 golang 看来一无是处。
我们编码是为了实现功能,不用管网络的评论或者是别人的说法,实践最重要,只要你用了之后觉得舒服觉得爽,就是你认为的可以。
其实我觉得就如同 DDD 类似,很多人觉得 DDD 是银弹,很多人认为 DDD 就是繁琐堆砌了一堆概念。而真正能评价的是深入使用过他们的人们。
其他参考
当然,兼听则明,偏信则暗,我在写本文之前,我也曾陷入自我怀疑,特地去采访了一些大厂、中厂的同学,得到的回答是这样的:”很多做业务的同学都使用了,做基架的有的没用”。当然也有部分做业务的同学并没有使用的情况,所以这也是为什么我敢说面向过程也没问题,大可放心。当然也仅供参考~
 微信
微信 支付宝
支付宝
