
K8S之CNI
之前我们解决了跨主机间容器间通信的问题,但是这也只能说我们铺好了路,村里通路了,但是其实作为 k8s 来说,还有好多其他的问题等待着我们解决。今天我们就通过这些问题来看看 k8s 的 CNI 的设计。CNI 到底究竟是个什么东西,到底是不是和你想的一样那么困难。
问题
IP 分配
我们知道 k8s 整个集群里面有许多的 pod 那么 IP 怎么分配呢?总不能分配着之后出现 IP 冲突了吧。k8s 集群里面是不是能不有一个类似 DHCP 的东西来管这个 IP 地址分配呢?
流量转发
当流量打到宿主机上时,应该有一个什么设备来快速将请求转到对应的 pod 才对吧?那么谁来做这个事情呢?
那为了解决上面的问题,我们一步步出发。
k8s 网络模型
首先有关 k8s 的网络模型,官网有下面的描述:(https://kubernetes.io/zh/docs/concepts/cluster-administration/networking/)
- 节点上的 Pod 可以不通过 NAT 和其他任何节点上的 Pod 通信
- 节点上的代理(比如:系统守护进程、kubelet)可以和节点上的所有Pod通信
备注:仅针对那些支持 Pods 在主机网络中运行的平台(比如:Linux):
- 那些运行在节点的主机网络里的 Pod 可以不通过 NAT 和所有节点上的 Pod 通信
也就是说所谓的 cni 实现必须满足这样的网络模型才可以,那么 CNI 究竟要做啥呢?
k8s 创建一个 pod 的具体过程
要说清楚 CNI 那就得从 pod 的创建的具体步骤来说了:
- 调用 CRI 创建 Pod 内的容器
- 第一个创建的容器是 pause:它就是一个永远阻塞的程序,作用就是占用一个 network namespace(目的就是先 hold 住这个 namespace),另一个作用是“收割”僵尸进程
- 创建其他用户需要的容器:共享之前 pause 创建的 network namespace,但是不初始化网络协议栈
- 创建容器网络设备并初始化:这就是 CNI 要做的,初始化 pause 的网络设备,也就是 pause 的 eth0 并分配 IP,pod 其他容器就是使用这个 IP 和其他容器通信的
CNI 到底是什么❓
我们知道了 CNI 要做的事情,以及 CNI 在模型中所处的位置,那么它究竟是什么呢?
CNI 全称 Container Networking Interface 容器网络接口,它其实就是一个接口,抽象了 k8s 网络操作的实现。
那么接口是什么样子的呢?
AddNetwork(net *NetworkConfig, rt* RuntimeConf)(types.Result, error)创建网络DelNetwork(net *NetworkConfig, rt* RuntimeConf)删除网络
其中 ADD 操作的含义是:把容器添加到 CNI 网络里;DEL 操作的含义则是:把容器从 CNI 网络里移除掉。
而对于网桥类型的 CNI 插件来说,这两个操作意味着把容器以 Veth Pair 的方式“插”到 CNI 网桥上,或者从网桥上“拔”掉。
CNI 插件如何使用
我们以 flannel 插件为例,部署起来其实非常的方便,就只需要
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
就可以了
1 |
|
我省略了其中有关 rabc 相关的资源,其实最重要的就是两个
- kube-flannel-cfg:这是个 configmap 记录了 flannel 的配置,注意其中 net-conf.json 的 Backend.Type 字段,用于标识当前 flannel 使用的是什么模式
- kube-flannel-ds:这是个 DaemonSet 所以每个节点都会有一个,它就是传说中我们的 flanneld 进程
所以现在 flannel 的部署使用是非常的简单了
为什么需要设计 CNI?
那为什么 k8s 不自己搞个方案让我们用就好了,非要设计成接口让我们自己找方案呢?
很简单,因为各有所需。下面举例两个方案
flannel 的 Host Gateway 模式
原理
我们知道 flannel 即使用了 vxlan 虽然比 udp 好了不少,但是还是存在瓶颈,因为你必须有一个封包和拆包的过程,而 host-gw 就是为了优化这个问题而来的。
host gateway 顾名思义就是拿宿主机作为网关,所以它的原理其实非常简单:
- 容器 A 内发包到 cni0
- cni 的 IP 匹配到 hostA 上的路由规则直接发送到 hostB
- hostB 的 eth0 收到后,根据 hostB 上的路由表转发到 hostB 上的 cni0
- 最终 cni0 将包转发到对应的容器 B
重点来了,其实在 host-gw 模式下,需要在宿主机上维护一个路由表,flannel 此时就是不断的监听 etcd 中对应子网的变化,将对应子网的下一跳写到对应的路由表中即可。
问题
因为使用路由表下一跳来设置的时候目标的时候是根据 mac 地址来找的,也就是设定的是下一跳宿主机的 mac 地址,而 mac 地址在二层网络是管用的,所以 host-gw 模式必须要求集群宿主机之间是二层连通的
实际中经常会出现两个宿主机在不同的 vlan 下,或者在不同的机房等等可能。
Calico 的 BGP
Calico 是一个基于 BGP 的纯三层的数据中心网络方案(BGP 就是在大规模网络中实现节点路由信息共享的一种协议。)题外话:说实话 BGP 这个词在大学学计算机网络的时候你应该听过,我对它的印象也是源于此。下面这张图是 Calico 官网找的架构图,我找资料的时候发现显然最新的 Calico 已经多了很多东西了 (https://docs.projectcalico.org/reference/architecture/overview)

原理
flannel 的 host-gw 模式是会在宿主机上维护一个路由表,那么讲道理来说,如果能有一个路由器来代替掉这个路由表的功能其实就可以了?对,其实很简单,Calico 的 BGP 简单的说就是在本机上模拟了一个类似路由器的功能来实现的。
它有几个重要的组件
Felix: 是一个 DaemonSet ,负责刷新主机路由规则和 ACL 规则等
BgpClient:读取 Felix 编写的路由信息,将这些路由信息分发到集群的其他工作节点上
Bgp Route Reflector:路由器反射器,简单来说,在网络规模大的时候如果单台机器就要维护全网的路由信息太难了,所以中间加入了 Route Reflector 协助去管理网络,BGP Client 只需要连接它就可以了
由于 Calico 是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的 NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑。
其次它不会在宿主机上创建任何网桥设备,Calico 的 CNI 插件会为每个容器设置一个 Veth Pair 设备,然后把其中的一端放置在宿主机上(它的名字以 cali 前缀开头)
网络拓扑图
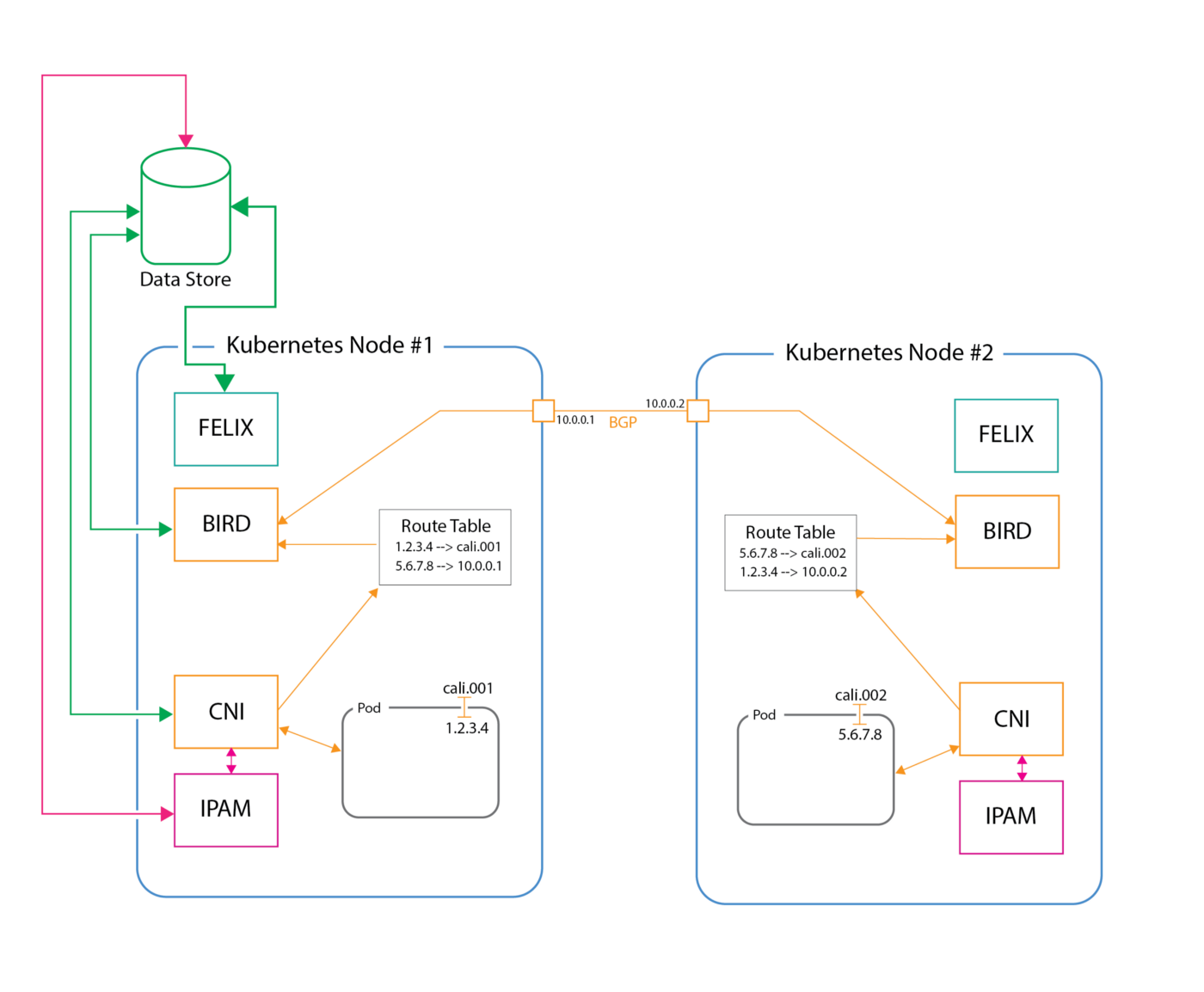
这次懒了,不想自己画了,网上找了一个,说一下链路吧
- 从 node1 中的 podA(1.2.3.4) 想要访问 node2 中的 podB(5.6.7.8)
- 首先 CNI 会为 podA 和 podB 创建 Veth Pair 一端插在 pod 里面,一端插在主机上,所以从 podA 中出来就走到了 cali.001上
- 接着由于 BIRD 会将网络中的路由信息同步并记录到对应的路由表中,所以要访问对应的 pod 就知道走哪里了,走到了宿主机的网卡上
- 然后重点来了,中间的网络路由是通过 BGP 协议实现的,并且其中如果有部署 Route Reflector 会通过它来中转路由信息
- 最后到达 node2 中,然后接着走类似的链路从而访问到 podB
总的来说,Calico 完全是利用了路由规则去实现的组网,利用宿主机协议栈去确保容器之间跨主机的连通性,没有 overlay,没有 NAT,相对的转发效率也比较高。
总结
当然 k8s 的 CNI 实现还有很多方案,各个网络方案都有自己的特点,而我们更多的时候选择一个合适的 flannel 或许就可以了,而关键在于我们需要明白它究竟帮助我们做了什么事情。网络这个东西,很多时候并不只是通就可以,还有很多性能、安全…的需求,不同的需求需要不同的网络方案去实现,而这也就是为什么 k8s 将设计 CNI 的原因,将网络的实现方案抽象,从而满足不同的使用场景。
参考链接
https://docs.projectcalico.org/reference/architecture/overview
https://k-grundy.medium.com/project-calico-kubernetes-integration-overview-a3a860cd974e
 微信
微信 支付宝
支付宝
