
再看golang垃圾回收
首先要说一些废话:
之前我已经有博客写过golang的垃圾回收相关的内容,虽然很简略,但是涵盖了整体的流程,现在为啥又来写一遍呢?一方面有一些政治(你懂得)因素在里面,一方面最近又再研究。那么问题来了,那么多博客已经写过了它,我怎么把它讲出花来呢?我思前想后,于是想出了几个独特的角度来重新诠释一下golang的垃圾回收。
那首先如果再把整个gc过程简单说一遍,可能就没有人愿意听了,但是golang的gc说简单也简单说复杂其实也有很多细节,如何做到有自己的想法呢?于是我就强行举例了几个问题。
问题&角度
在研究golang垃圾回收的时候,你有没有想过下面几个问题
- golang如果有两个对象循环互相引用,是否会出现永远回收不了的对象?
- golang的gc标记方式为什么用bfs而不是dfs?
- 是否有可能永远不触发gc?
- 为什么golang的gc不整理、不分代?
个人理解
首先说明一下,这些问题都是我自己想的,也没有什么所谓的正确答案,所以下面也是我的个人理解,如果有问题可以在下方留言进行讨论。
问题1
- golang如果有两个对象循环互相引用,是否会出现永远回收不了的对象?
为什么会想到有这个问题呢?因为有人曾经问过,为什么golang里面不能有包的循环引用?其实这两个问题并没有相关性。。。包的循环引用和对象的循环引用是不一样的。我们来看看下面的代码。
1 | package main |
首先这样的代码肯定是可以编译通过的,而且明显两个对象就有互相引用,但是这样会导致gc无法回收这两个对象吗?
明显不可能。。。
因为golang的gc不是使用引用计数来完成的标记,并不是通过计算一个对象的引用数来计算一个对象是否会被回收,而是从root开始来进行寻找标记的。我们看下面这个图就很明确了。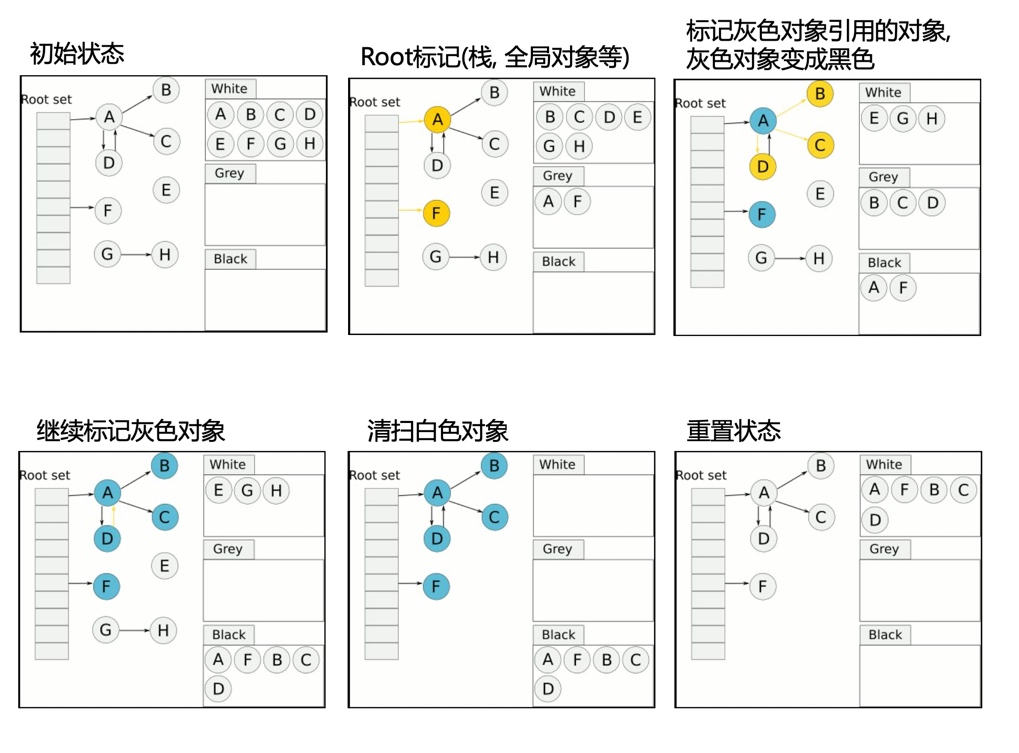
其中A和D明显是相互引用的,只要A不用了,那么两者就会被回收。
问题2
- golang的gc标记方式为什么用bfs而不是dfs?
首先bfs是广度优先搜索,dfs是深度优先搜索,我们知道我们的三色标记是一层层往下走的,那为什么会这样设计呢?
这个问题没有明确的答案,我说一下我个人的理解。
- 针对gc来说,其实对象是很多的,而对象直接的引用层级其实是不深的,说白了,如果把整个对象的引用比作一颗树的话,那么树的高度或者说深度是不会很高的,而root会很多。
- 后期引用的变动往往都发生在最底层,如果使用dfs那么很有可能已经被标记过的对象发生了引用变动,可能会影响部分性能。
- dfs需要递归实现,那么函数的调用必然会有入栈出栈,所以不太合适。
问题3
- 是否有可能永远不触发gc?
我们知道触发gc的条件有几个:
- 达到GC百分比上限
- 达到一定的时间2分钟(sysmon)
- 使用runtime.GC()
那么是否有办法实现永远不触发gc呢?有的!
来看看下面这个代码:
1 | package main |
如果我们使用GODEBUG="gctrace=1"打印出gc日志会发现,没有任何的输出。为什么呢?
1 | go func() { |
原因就在这个地方,因为golang在想要gc的时候,需要保证所有的协程走到一个安全点,所谓的安全点是需要你有任何的函数调用都可以。而这里是没有任何函数调用的,也就是说没有安全点。所以golang没有办法触发gc,当我们在其中加入任意方法之后,就可以触发gc了。
所以这也让我们在写程序的时候要注意,千万不能有死循环,并且当中没有任何函数调用(虽然在实际中很少存在)
问题4
- 为什么golang的gc不整理、不分代?
下面是来自源码中的一段:
- The GC runs concurrently with mutator threads, is type accurate (aka precise), allows multiple GC thread to run in parallel. It is a concurrent mark and sweep that uses a write barrier. It is non-generational and non-compacting. Allocation is done using size segregated per P allocation areas to minimize fragmentation while eliminating locks in the common case.
其中明确说明了是非分代和非整合的算法。
对于这个问题,首先我不得不说的是,分代确实能很好的提高gc的效率,因为大多数对象使用的时间是很短的,而长时间占用的对象是很少的,这也是java中分代的原因。而对于整理,整理的话有利于内存的管理和回收,当对象被回收之后,会出现很多的内存碎片,而整理可以很好的重新规范内存,回收那些不需要的页。
那么golang为啥不做呢?首先是复杂,我们看java分代回收的实现就非常的复杂,实现起来需要很大的力气,而当前的golang的gc效率已经可能已经满足需求了。然是就是整理,其实整理这块是由内存管理模块来管理的,而golang中的内存管理在分配的阶段已经利用了最小化的原则,每次给到的都是合适的大小,所以整理这块就交由他们进行来管了,gc这块只负责回收就可以了。
最后来个tool
最后补充一个tool之前博客中只是说用gctrace来输出gc日志,而没有可视化的展示,而其实有这样的工具可以满足这样的要求。
1 | package main |
在你的项目中添加如下的代码,然后在运行一段时间之后就可以通过go tool trace trace.out命令来在页面上查看整个项目gc的情况了。
 微信
微信 支付宝
支付宝

